Database Version Control
Database version control
Writing this I am presupposing that whoever is reading this knows about this topic, but to summarize, there’s been a recent movement that has taken a lot of ground on regards to versioning your database as you would code. I highly favor this line of thinking and I will be exposing some tools or approaches, since often people only know one option they have in this regard.
The logic to this concept is very simple, the database is a dependency of your application and just like you would with any other dependency, you want to know which version you have, because if you don’t, things will crash.
Migrations and code first migrations are one of the practical implementations of this concept. They consist of writing database changes like you would commits in a version control repository of any sort. Migration frameworks vary mainly in two things, they are either SQL driven or they use some sort of code convention to generate the database entities without writing SQL.
The “code first” approach
I am going to be using entity framework core’s code first approach as an example, but it is definitely not alone in the scope of migration frameworks.
Entity Framework allows you to turn a C# entity class into a table using conventions, data annotations and/or the fluent API. This can be a very powerful way of defining data models for your application.
A simple class like this in C#:
public class Customer
{
[Key]
public int Id { get; set; }
[StringLength(50)]
public string Name { get; set; }
[StringLength(12)]
public string PhoneNumber { get; set; }
public int Age { get; set; }
public DateTime CreationDate { get; set; }
public DateTime UpdateDate { get; set; }
}
Can produce a database table with matching names and types. Other conventions and mechanisms can be used to add further customization and control over the generated SQL.
Pros
- Simple and fast.
- Great for quick iterations.
- Requires little knowledge of SQL for those more junior on your team.
Cons
- Controlling the output SQL is hard since it requires your entire team to know how to use the fluent API well.
- Collaborating with a DBA or a SQL Developer is even harder since the ability doesn’t translate well to them.
The “Database First” approach
Alright, so this one comes from the old days of Entity Framework 6. Back then you could generate an EDMX file based on your existing DB, that would also eventually generate model classes and your database context. The idea behind database first is that you make your changes in SQL with whatever strategy your team may have and then you bring the changes into your code.
In Entity Framework Core, working this way is possible. It comes with caveats, but it is possible. You can use the command:
Scaffold-DbContext 'Your Connection String Here' Microsoft.EntityFrameworkCore.SqlServer
In your package manager console and that will generate all entity framework files into the project you ran the command as.
Just make sure to select the project you want to generate your reversed engineered files for your data access code.
The command also allows you to select the name of the generated DbContext class and the folder it will be generated in.
I’ve used this method alongside Entity Framework Core migrations. One annoying thing about this is that you will have to manually update your connection string and constructor configuration everytime you do this. The reverse engineer will remove all previous changes to your models and Db Context class.
Entity Framework migrations can be used with plain SQL written by you. See the example below.
public partial class YourMigrationName : Migration
{
protected override void Up(MigrationBuilder migrationBuilder)
{
migrationBuilder.Sql(@"Your SQL Here");
}
protected override void Down(MigrationBuilder migrationBuilder)
{
migrationBuilder.Sql(@"More SQL over here");
}
}
The other downside is that your team can be tempted into using code first migrations (since it still is a possibility), and thus lack of control of your SQL as well as synchronization problems among your team. Another problem I encountered with this is that you are generating as many files as you have database tables, than can easily lead to compile errors if many database objects change names. These errors will then not let you run migrations because for EF Core migrations to run, you application needs to compile. This is not impossible to solve, but it is very very tedious to deal with.
If you are using this approach, you most likely want control of your SQL, so while it is possible to do this in EF Core, it is not the most streamlined method by any means.
In my opinion, I don’t think the EF Core team expected many people to do this. While it is a functioning method, it is much more cumbersome than Code First.
Pros
- Control over your SQL
- Easier to work with a DBA than Code First. (Though not 100% ideal)
- Relatively easy to keep your data access code and your database in sync.
Cons
- A poorly written migration or a dumb mistake in database naming can potentially cost you many hours to solve properly.
- This method is not well streamlined and requires getting used to, both for you and your team.
- It does not allow for bi-directional changes in the database. All changes must come through migrations for them to get versioned and stay syncronized accross the team.
- EF Core does offer support for the usage of stored procedures and views, but constantly regenerating your DB Context can greatly hinder your work with these since the scaffold command only takes tables and indexes into account.
SQL Server Data tools (SSDT)
This is in my opinion the superior method of versioning your database when working with .Net. It allows you easy access to bi-directional change management in databases.
This method works using a Database project. First you hit: “Add new project”, then you select the following project:
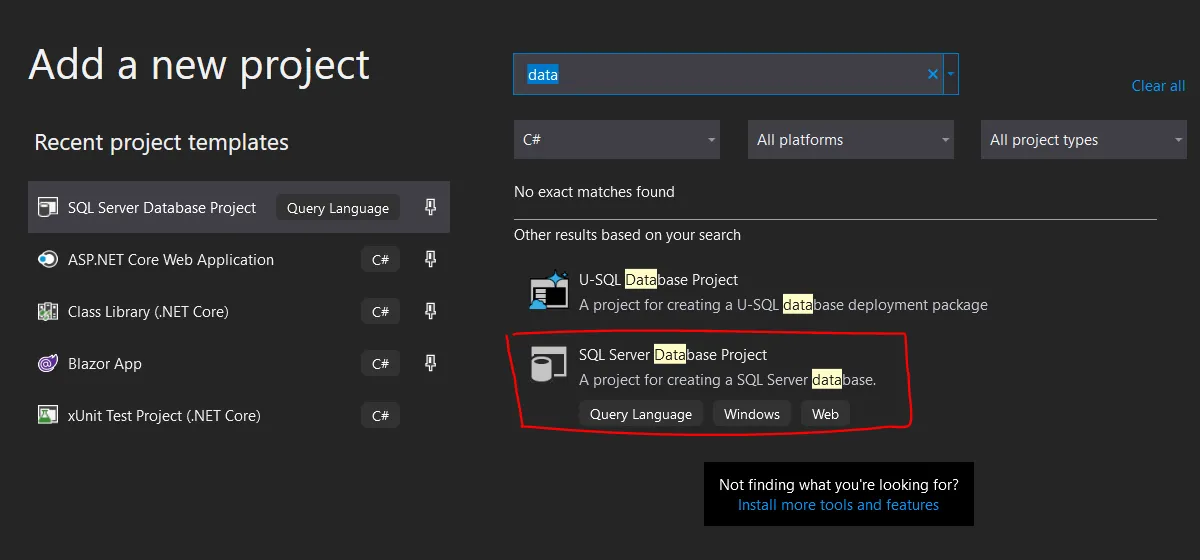
This kind of project allows you to version your entire database as SQL Create Scripts. Then you can use the “Schema Compare” function. This essentially allows you to make live diffs between your database project and a target database which can come in very handy and is very powerful.
With this kind of project you can work very flexibly. Want to start with an existing database? Easy. Want to start modelling your database in the database project as you go? Also easy. Want to do both? Go right ahead.
This offers the most streamlined approach when you want to work with someone that does your SQL while the rest of the team focuses on the code. So far it has lead me to the least frustration since the tooling is very versatile and robust.
Pros
- Fully streamlined approach to work with a DBA or anyone with heavy SQL knowledge.
- Bi-directional change management. You can receive changes from someone on the data side, or a developer can make a change and pass it to the SQL person with no problems.
- The tool is very powerful and robust. Very little work is required with the upgrade script is required.
Cons
- Can only be used with SQL Server
- Not very useful if you’re embracing the code first model.
SSDT for other database engines
Let’s say you have a database in Postgres or MySQL. SSDT won’t work for you. Sadly Microsoft made this tool only for their poster boy db. However, that doesn’t mean that there aren’t options if you want a SQL driven database version control tool. DB Forge from Devart has a tool for both Postgres and MySQL, it is however a payed tool, but it is an option. For MySQL, Skeema is an open source solution for MySQL. Postgres Compare is a cheap tool recommended by none other than Scott Hanselman himself. If you want something open source for Postgres then sqitch is an option.
Final thoughts
I am personally biased towards tools similar to SSDT. There is a plethora of options in the area and there is a lot of space for more high quality open source tools that help us have similar ease of use to that of SSDT for open source DB Engines.
My point at the end was to show that there are very many ways of handling database version control, which one you choose depends on your team, your company, the skills of your developers and what you foresee as the future of your applications.